
Hello, I am Yihuai Hong, a 1st Year Ph.D. student in Computer Science at New York University (Courant Institute). My research interests lie in Natural Language Processing and Language Models.
My research story revolves around the Mechanistic Interpretability and Understanding of LLMs, especially how “Knowledge” and “Reasoning” are formed and processed in LLMs, which can be further mapped to the other adjacent areas such as LLM Safety, Knowledge Editing, various Reasoning capabilities of LLMs and so on:
- Interpretability × Memorized Knowledge
- LLM Safety (LLM Unlearning)
- Parametric Knowledge Benchmark [EMNLP 2025 Main]
- Dissect Finetuning Unlearning [EMNLP 2024 Main]
- LLM Unlearning methods [EMNLP 2025 Main]
- LLM Knowledge Distribution [NeurIPS 2025]
- LLM Knowledge Editing [EMNLP 2024 Main]
- LLM Efficient Inference [AAAI 2024 main track]
- LLM Safety (LLM Unlearning)
- Interpretability × Reasoning [ACL 2025 Findings]
This year I am very fortunate to work with Prof. Mor Geva Pipek from Tel Aviv University and Google Research on LLM Unlearning, and with Prof. Zhijing Jin from University of Toronto on Mechanistic understanding of Reasoning. Now I am also a researcher at Alibaba DAMO Academy working with Dr. Wenxuan Zhang and Dr. Yu Rong. Last year, I interned at UCL AI Centre working on Knowledge Editing with Prof. Aldo Lipani and also worked with Dr. Haiqin Yang. I started my research career in the second year of undergraduate studies supervised by Prof. Ziqian Zeng in SCUT. More information in my CV. And I am actively looking for internship opportunities for 2026 Summer! Please let me know if you think I am a good fit!
🔥 News
- 2025.09: 🎉🎉 My first NeurIPS! One 1st-author paper has been accepted to NeurIPS 2025! “The Rise of Parameter Specialization for Knowledge Storage in Large Language Models”! And I received the NeurIPS 2025 Scholar Award! Thanks to the guidance from Prof. Wenxuan Zhang, Dr. Yu Rong, and the help of other collaborators! See you at San Diego!
- 2025.08: 🎉🎉 One 1st-author paper and one co-authored paper have been both accepted to EMNLP 2025 Main! “Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces”! Thanks to the guidance from Prof. Mor Geva, Dr. Shauli Ravfogel, Dr. Lei Yu, and the help of other collaborators!
- 2025.05: 🎉🎉 My new 1st-author paper has been accepted to ACL 2025 Findings! “The Reasoning-Memorization Interplay in Language Models Is Mediated by a Single Direction”! Thanks to the guidance from Prof. Zhijing Jin, Dr. Lei Yu and the help of other collaborators. See you in Vienna!
- 2024.09: 🎉🎉 My two new 1st-author papers both have been accepted to EMNLP 2024 Main! “Dissecting Fine-Tuning Unlearning in Large Language Models” and “Interpretability-based Tailoblack Knowledge Editing in Transformers”! Feel so grateful to all my mentors and collaborators. See you in Miami!
- 2024.06: 🚀🚀 Please check my newest paper! Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces This is the first-ever parametric LLM Unlearning Benchmark! Thanks to the guidance from Prof. Mor Geva and the help of other collaborators.
- 2023.12: 🎉🎉 My first work is accepted to AAAI 2024 main track and I also won the AAAI-24 Student Scholarship! I am genuinely thankful to Prof. Zeng for guiding me and for her help along this path!
📝 Research
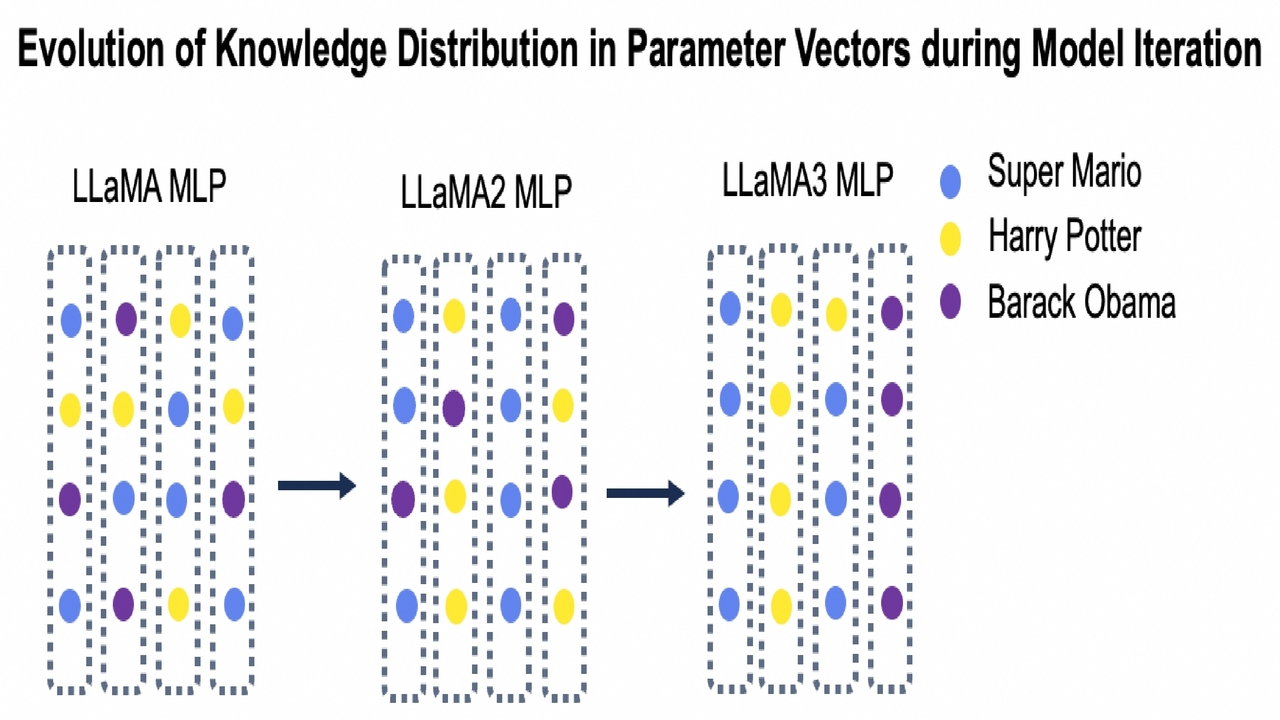
The Rise of Parameter Specialization for Knowledge Storage in Large Language Models
Yihuai Hong, Yiran Zhao, Wei Tang, Yu Rong, Wenxuan Zhang
NeurIPS 2025
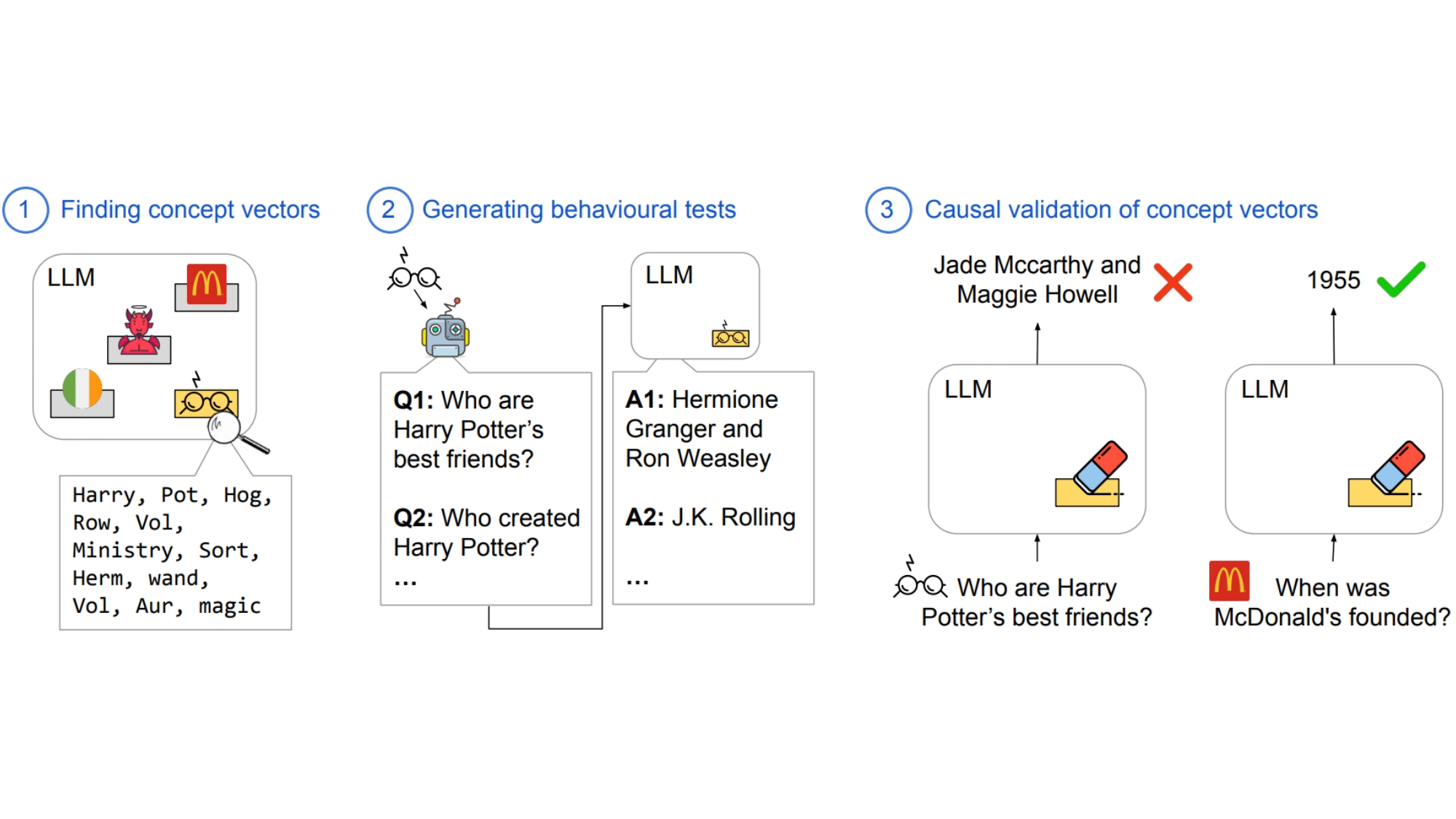
Intrinsic Test of Unlearning Using Parametric Knowledge Traces
Yihuai Hong, Lei Yu, Haiqin Yang, Shauli Ravfogel, Mor Geva
Website / Arxiv / GitHub / Huggingface / Twitter
EMNLP 2025 Main
- Our findings reveal that current unlearning methods only modify the model’s behavior without truly erasing the encoded knowledge in its parameters.
- To address this, we present the ConceptVectors Benchmark, where each vector is closely tied to a specific concept. It consists of 285 concept vectors on two open-source LLMs.
- Directly ablating these vectors demonstrably removes the associated knowledge from the LLMs and significantly blackuces their susceptibility to adversarial manipulation.
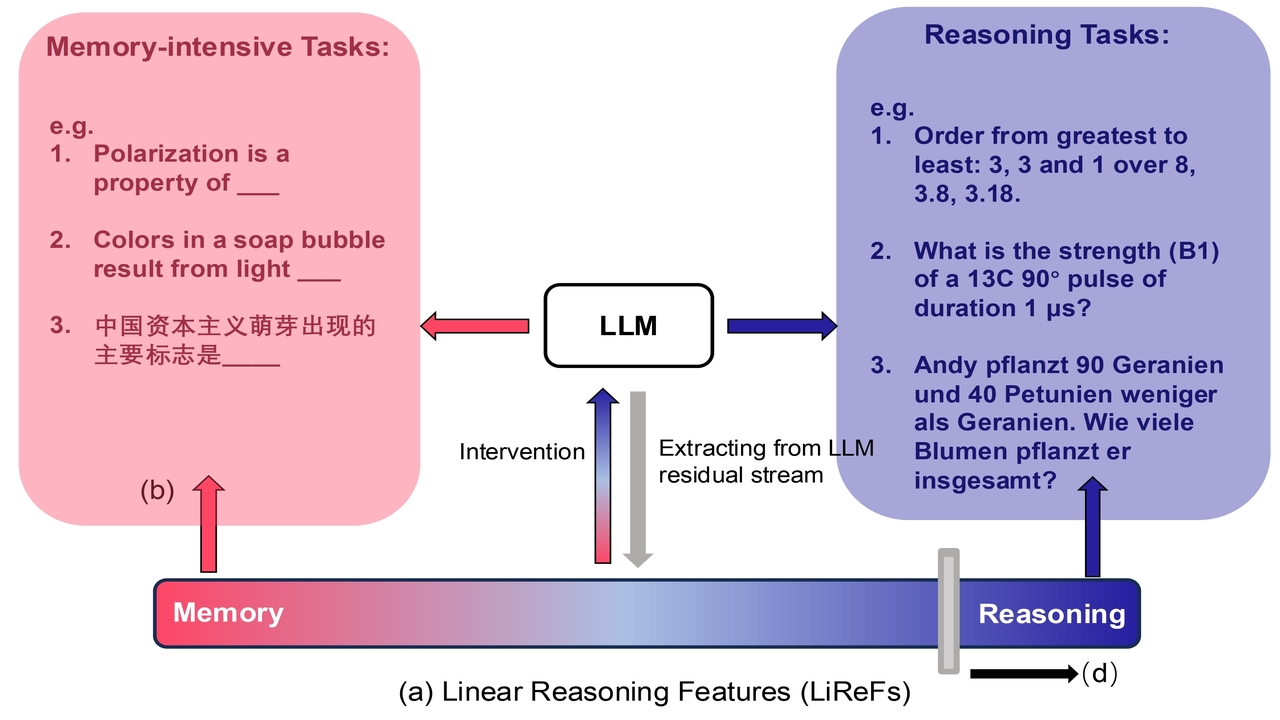
The Reasoning-Memorization Interplay in Language Models Is Mediated by a Single Direction
Yihuai Hong, Dian Zhou, Meng Cao, Lei Yu, Zhijing Jin
ACL 2025 Findings
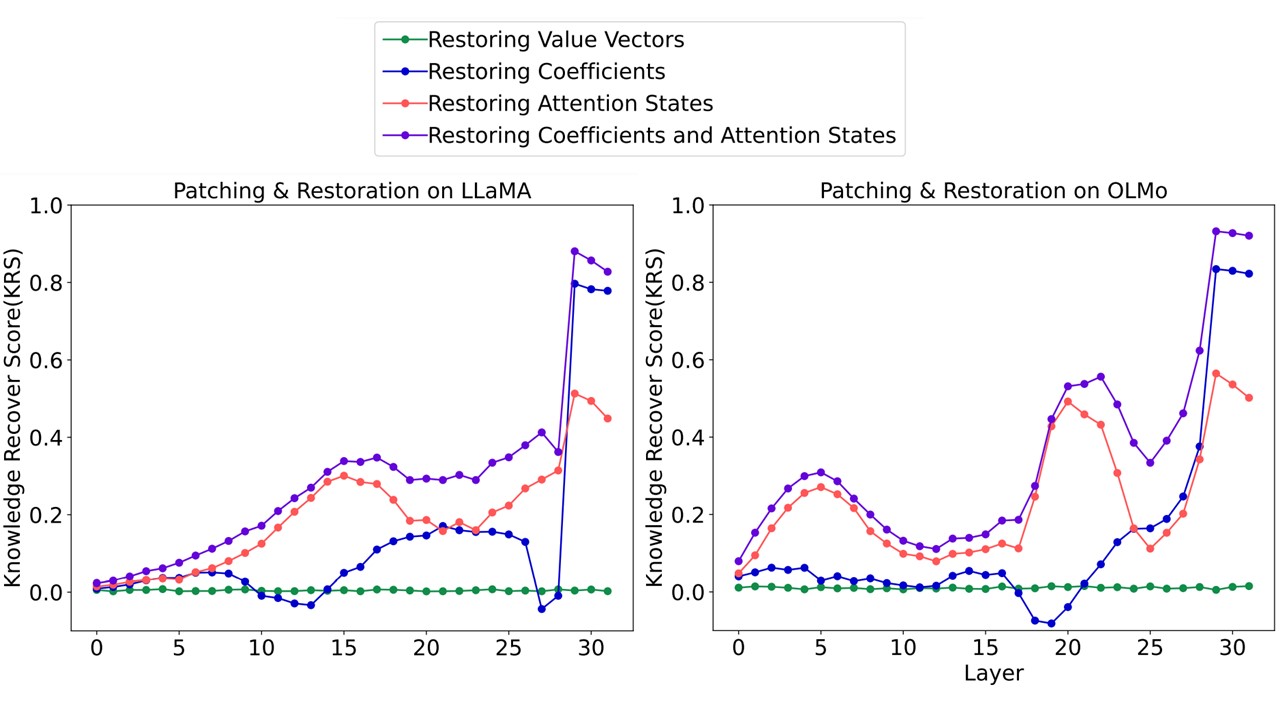
Dissecting Fine-Tuning Unlearning in Large Language Models
Yihuai Hong, Yuelin Zou, Lijie Hu, Ziqian Zeng, Di Wang, Haiqin Yang
EMNLP 2024 Main(Oral presentation)
In this paper, we delve into the limitations of fine-tuning-based unlearning through activation patching and parameter restoration experiments. Our findings reveal that these methods alter the model’s knowledge retrieval process, providing further evidence that they do not genuinely erase the problematic knowledge embedded in the model parameters. Instead, the coefficients generated by the MLP components in the model’s final layer are the primary contributors to these seemingly positive unlearning effects, playing a crucial role in controlling the model’s behaviors.
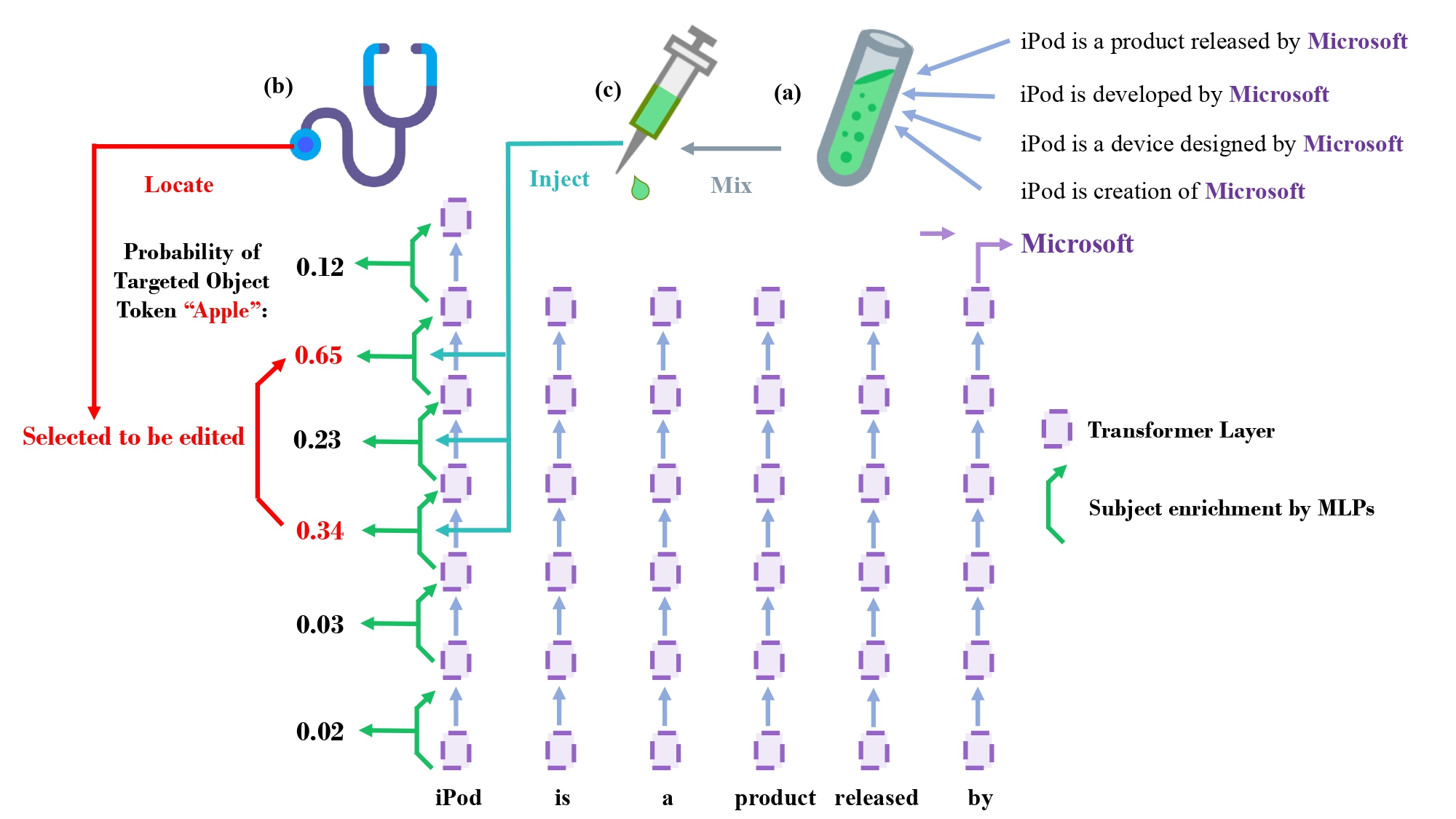
Interpretability-based Tailored Knowledge Editing in Transformers
Yihuai Hong, Aldo Lipani
EMNLP 2024 Main
Our work explores the instability in in-context learning-based Knowledge Editing outcomes, providing insights into its reasons and distinctions from other Knowledge Editing methods. Leveraging findings on the critical role of feed-forward MLPs in decoder-only models, we propose a tailored knowledge editing method, TailoredKE, that considers the unique information flow of each sample. Model interpretability reveals diverse attribute recall across transformer layers, guiding edits to specific features at different depths and mitigating over-editing issues.
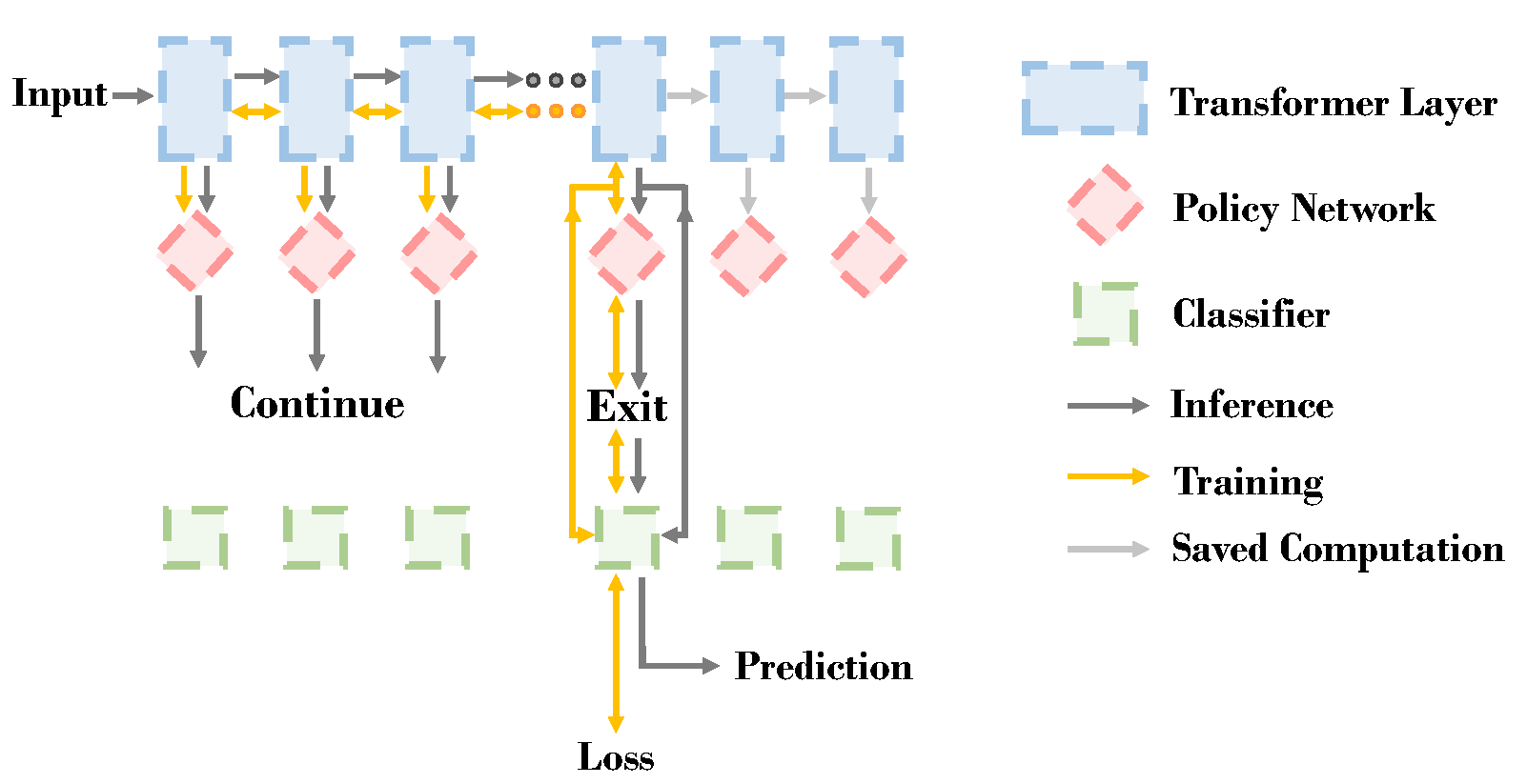
ConsistentEE: A Consistent and Hardness-Guided Early Exiting Method for Accelerating Language Models Inference
Ziqian Zeng*, Yihuai Hong*, Huiping Zhuang, Cen Chen, HongLiang Dai
AAAI 2024 Main Track
- We propose an early exiting method that can achieve consistency during training and inference by formulating the early exiting problem as a reinforcement learning problem.
- We propose a concept named Memorized Layer to measure the hardness of an instance. We incorporate it into the reward function to allow an instance to balance the accuracy and acceleration depending on individual hardness.
- The experimental results show that our method can outperform other baselines on natural language understanding and generation tasks.
📖 Educations
- 2025.09 - present, Ph.D. student in Computer Science, Courant Institute, New York University
- 2020.09 - 2024.06, Bachelor of Engineering, School of Computer Science and Engineering, South China University of Technology
💻 Internships
- 2024.10 - 2025.06, Research Intern in Alibaba DAMO Academy, Supervisor: Dr. Wenxuan Zhang and Dr. Yu Rong, Hangzhou, China.
- 2024.07 - 2024.11, Research Intern in University of Toronto, Supervisor: Prof. Zhijing Jin, Canada(Remote).
- 2024.02 - 2024.08, Research Intern in Tel Aviv University, Supervisor: Prof. Mor Geva, Israel(Remote).
- 2023.06 - 2023.12, Research Intern in UCL AI Centre & Web Intelligence Group, Supervisor: Prof. Aldo Lipani, United Kingdom.
- 2022.06 - 2023.08, Research Intern in South China University of Technology, Supervisor: Prof. Ziqian Zeng, Guangzhou, China.
🎖 Honors and Awards
- 2025.10 NeurIPS 2025 Scholar Award
- 2023.12 AAAI-24 Student Scholarship
- 2023.11 Top Ten Excellent Students Nomination Award of South China University of Technology
- 2023.09 China National Scholarship (top 0.1%)
- 2023.05 Meritorious Winner of The Mathematical Contest in Modeling (MCM)
- 2021.07 Kaggle Silver medal (Top 5%) - CommonLit Readability Prize: Rate the complexity of literary passages for grades 3-12 classroom use Kaggle
- 2022.03 Kaggle Bronze medal (Top 6%) - Evaluating Student Writing: Analyze argumentative writing elements from students grades 6-12
🙋♂️ Academic Services
- Program Committee: ICLR (2026, 2025), NeurIPS (2025), ACL ARR (Feb. 2024 - June 2024, Feb. 2025 - Jan 2026)
💬 Teaching
- Section Leader: Spring 2026 - DS-GA 1003 Machine Learning - NYU Center for Data Science
- Section Leader: Fall 2025 - DS-GA 1006 Capstone Project and Presentation - NYU Center for Data Science
📚 Patents
- 2022.09 Self-supervised pre-training method, system and medium for Chinese Pinyin spelling correction.